Как устроен HashMap в Java 8?

HashMap - это реализация интерфейса Map на основе хэш-таблицы. Хэш-таблица использует хэш-функцию для вычисления индекса, также называемого хэш-кодом, в массиве сегментов или ячеек, из которых можно найти желаемое значение. Во время поиска предоставленный ключ хэшируется, и результирующий хэш указывает, где в хэш-таблице хранится соответствующее значение.
static class Entryimplements Map.Entry {
final K key;
V value;
Entry next;
int hash;
} Как вы видите, этот внутренний класс имеет четыре свойства. key, value, next и hash.
- key: в нем хранится ключ элемента и он не изменяемый.
- value: содержит значение элемента.
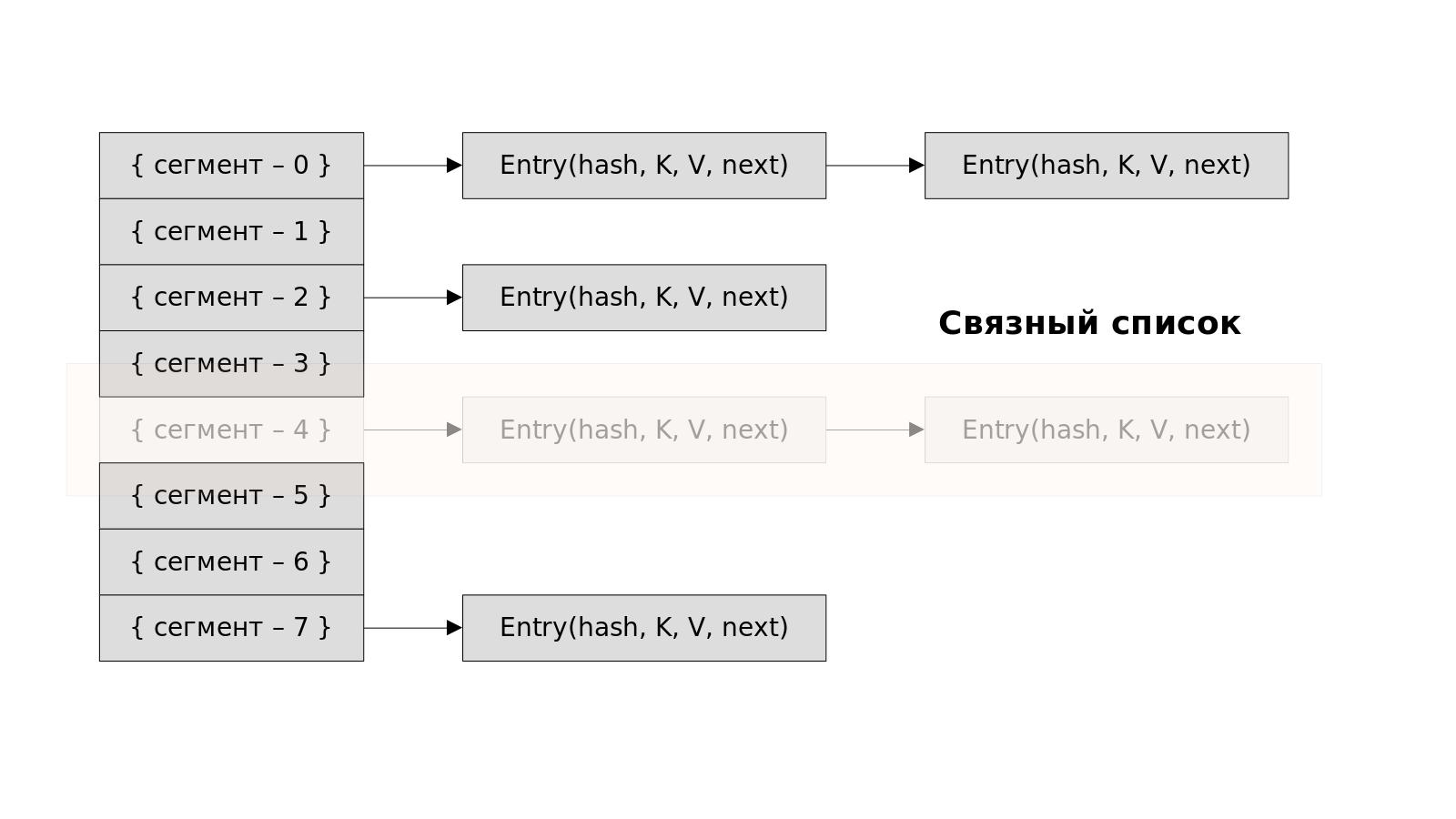
- next: содержит указатель на следующую пару ключ-значение. Благодаря этому атрибуту пары ключ-значение сохраняются в виде связанного списка (Linked List).
- hash: содержит хэш-код ключа.
Когда количество пар ключ-значение в HashMap превышает определенный порог, определяемый коэффициентом загрузки, HashMap необходимо изменить размер своего внутреннего массива и перехэшировать все пары ключ-значение. Этот процесс также называется изменением размера.
Цель изменения размера состоит в том, чтобы обеспечить сохранение коэффициента загрузки ниже определенного порогового значения для предотвращения чрезмерных столкновений, которые могут привести к снижению производительности. За счет увеличения емкости (количества сегментов) HashMap и перераспределения пар ключ-значение коэффициент загрузки снижается, и HashMap может сохранять свою эффективность.
Процесс изменения размера и перехэширования
Превышение порогового значения коэффициента загрузки
По мере добавления элементов количество пар ключ-значение увеличивается. Когда количество элементов превышает определенный порог, определяемый коэффициентом загрузки, HashMap решает изменить размер своего внутреннего массива для поддержания эффективности. Коэффициент загрузки по умолчанию равен 0,75, что означает, что изменение размера происходит, когда количество элементов превышает 75% от текущей емкости.
Рассчет новой пропускной способности
При превышении порогового значения коэффициента загрузки хэш-карта вычисляет новую емкость, удваивая текущую емкость. В этом примере предположим, что текущая емкость равна 16, тогда новая емкость будет равна 32.
Создание нового массива
HashMap создает новый массив с новой емкостью (32 ячейки). Все ячейки в новом массиве изначально пусты.
Перехэширование и перемещение элементов
- Для каждой пары ключ-значение в старом массиве HashMap пересчитывает хэш-код ключа, используя новую емкость (32 сегмента), и находит соответствующий сегмент в новом массиве.
- Затем пара ключ-значение перемещается из старого блока в новый блок в массиве с измененным размером.
- Во время этого процесса хэш-коды ключей перефразируются на основе новой емкости, что может привести к другому распределению блоков по сравнению со старым массивом.
Связанные списки со сбалансированными деревьями (необязательно)
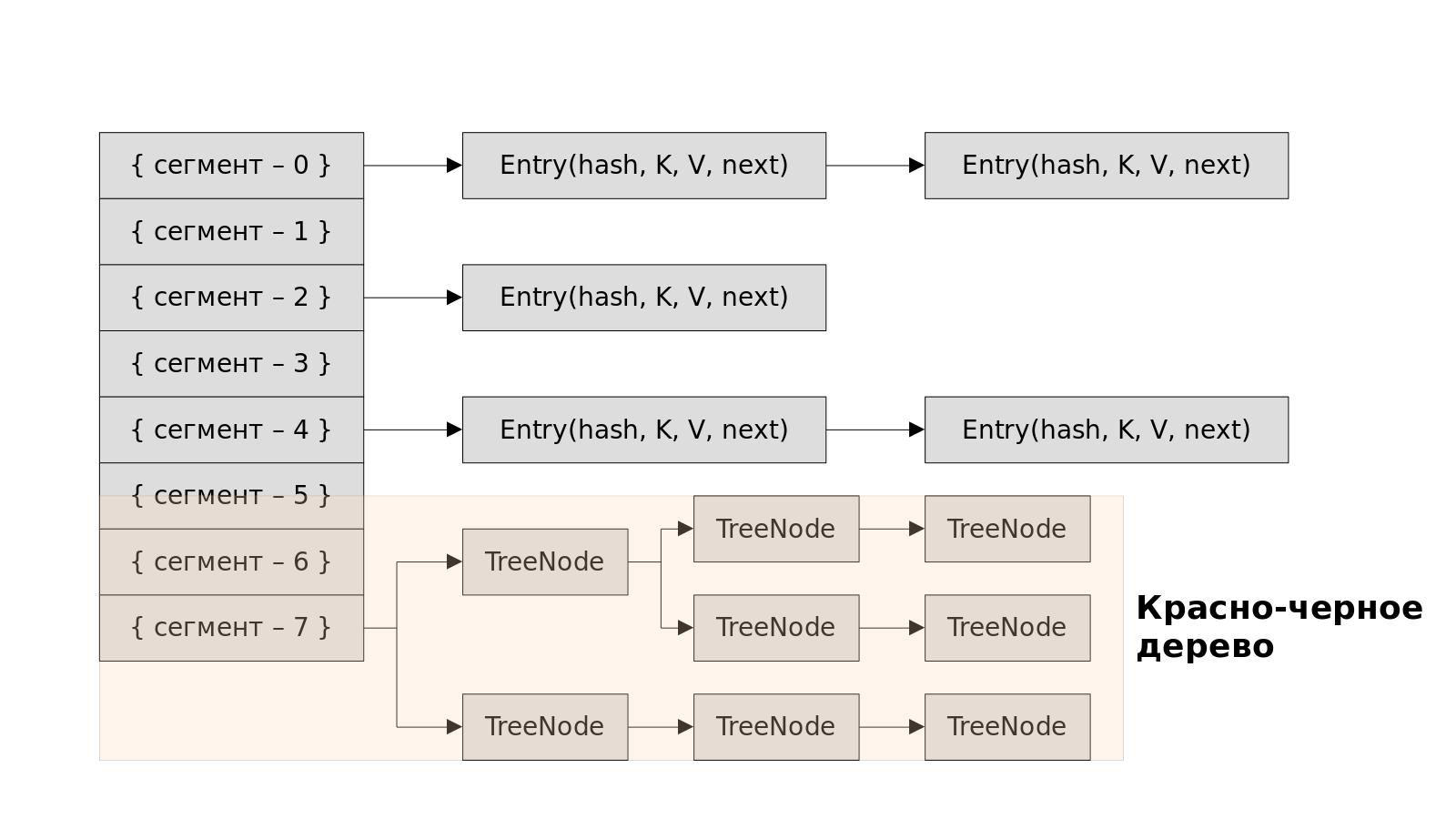
- В современных версиях Java (начиная с Java 8), если записи в одном сегменте достигают порогового значения (TREEIFY_THRESHOLD, значение по умолчанию 8), то Map преобразует внутреннюю структуру сегмента из связанного списка в красно-черное дерево. Все экземпляры Entry преобразуются в экземпляры TreeNode.
- Чтобы повысить производительность поиска, HashMap преобразует связанный список в сбалансированное дерево (красно-черное дерево) во время повторного хэширования, обеспечивая более эффективный поиск (O(log n)) вместо линейного поиска (O(n)).
- Преобразование из связанного списка в сбалансированное дерево происходит во время повторного хэширования и выполняется для любых сегментов, размер которых превышает пороговое значение (8 или более записей).
- Обратите внимание, что когда количество узлов в корзине становится меньше, чем UNTREEIFY_THRESHOLD, дерево снова преобразуется в LinkedList. Это помогает сбалансировать производительность и использование памяти, поскольку TreeNodes занимает больше памяти, чем экземпляры Map.Entry. Таким образом, Map использует дерево только тогда, когда есть значительный прирост производительности в обмен на потерю памяти.
Что такое Красно-черные деревья и для чего они используются?
Красно-черные деревья - это самобалансирующиеся деревья бинарного поиска. Красно-черное дерево гарантирует, что длина деревьев бинарного поиска всегда равна log(n), несмотря на добавление или удаление новых узлов.
Основные преимущества использования красно-черной древовидной структуры заключаются в том, что в одном и том же блоке находится много записей. Для выполнения операции поиска в Java 7 потребуется O(n) со связанным списком. В то время как в java 8 та же операция поиска в дереве будет стоить O(log(n)).
Недостатки: Дерево действительно занимает больше места, чем связанный список.
При наследовании корзина может содержать как узел (входной объект), так и древовидный узел (красно-черное дерево).
- Если для данного сегмента существует более 8 узлов, связанный список преобразуется в красно-черное дерево. Это представлено следующим кодом в классе HashMap:
static final int TREEIFY_THRESHOLD = 8;- Если для данного сегмента имеется менее 6 узлов, то дерево может быть преобразовано в связанный список.
static final int UNTREEIFY_THRESHOLD = 6;
Комментарии (0)
Комментарии могут оставлять только зарегистрированные пользователи.
Пока нет комментариев. Станьте первым!